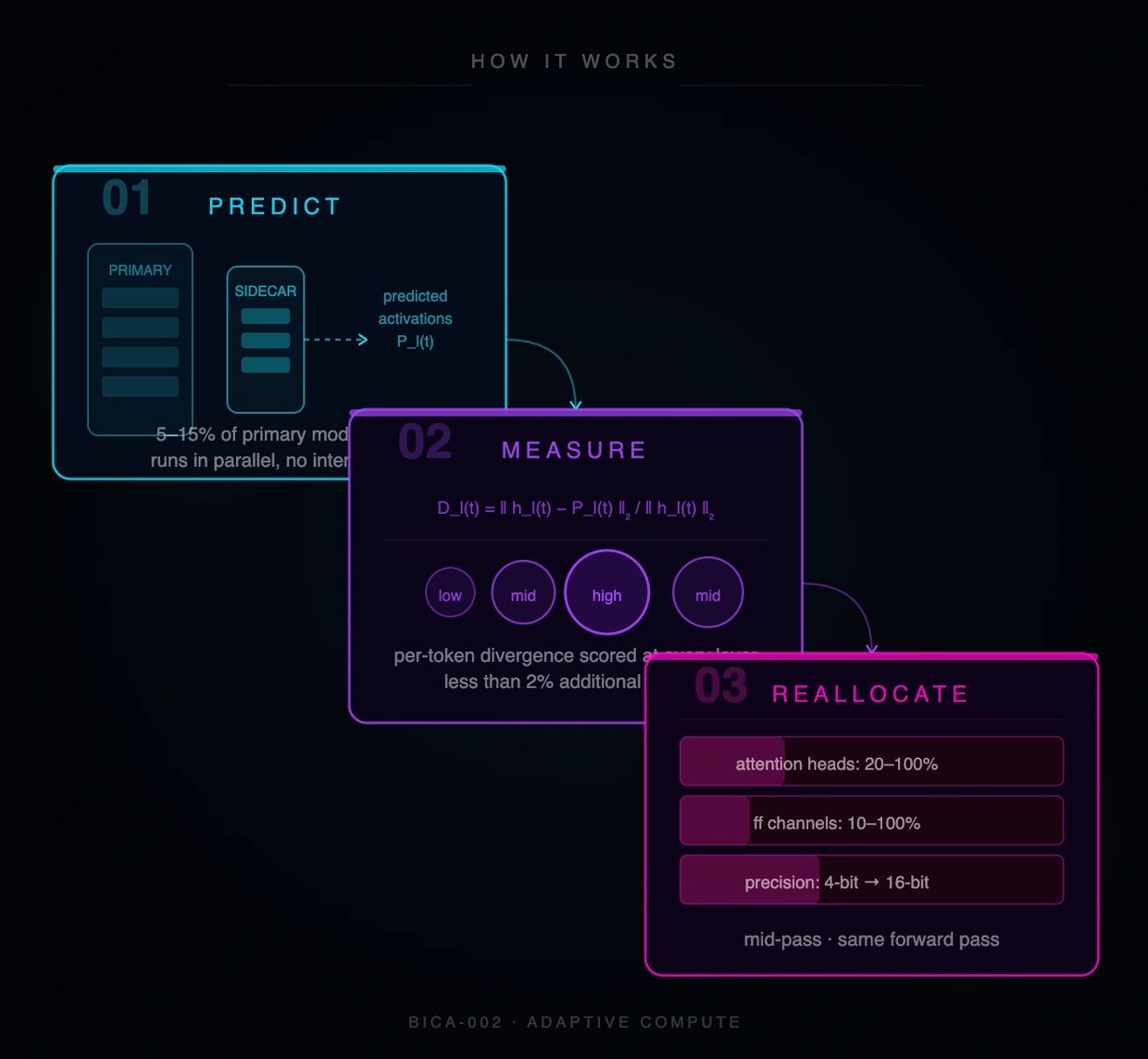
KEY CAPABILITIES
- Sidecar Architecture — 5–15% of primary model size. Runs in parallel. No inference interruption.
- Within-Token Reallocation — Decisions made mid-pass, not before. Responds to evidence as it accumulates.
- Frozen-Model Deployment — Retrofits onto existing models as adapter modules. No retraining required.
